Booming Open Source Chinese-Speaking LLMs: A Closer Look
This post is based on a presentation I delivered at Seoul National University in early April 2023 with some modifications but some information might not be the most up-to-date. Slide can be found here.
Open Source Progress in China
Over the past year, the Chinese-speaking open-source community has made significant progress. I had the opportunity to observe the entire ecosystem’s boom and have been working closely with key projects. Many developments occur, but they are seldom discussed outside China, as most conversations take place in Chinese on platforms like WeChat rather than Twitter or Discord. I’m eager to share what I’ve learned. And I’m also keen to discover more about developments in Korea. We’re observing an increasing number of text generation models being uploaded to Hugging Face from Korea, and I hope that by next year, we can discuss a boom in open-source Korean-speaking LLMs. :-)
Quiz: Can you name a few Chinese-speaking LLMs you’ve heard of?
Some response from the audience include Baichuan, 01, and QWen.
A report from Reuters early last year noted that more LLMs were released in China than in the US by mid 2023.

In 2024, the release pace has quickened remarkably. Before the Lunar New Year in January, new open-source model series were released every one to two days, each including multiple models of different sizes (e.g., 6B, 34B), stages (e.g., base, chat) and quantization (e.g., 16bit, 8bit). This list does not include closed-source models such as Baichuan3 and GLM4.
These models not only speak excellent English and Chinese but some also aim to serve multiple languages. RWKV, a famous linear attention or State Space Model (SSM), targets over 100 languages. OrionStar includes built-in support for Korean and Japanese during the pre-training stage. QWen provides strong support for Southeast Asian languages such as Vietnamese and Thai.
Thomas Wolf, Hugging Face’s CSO (Chief Science Officer), recently highlighted on Twitter how OpenBMB’s MiniCPM and DeepSeek Math not only opened their model weights but also shared valuable knowledge and insights that benefit the entire ecosystem.
In terms of performance, the Chinese-speaking models are excelling. The Open LLM Leaderboard, managed by Hugging Face, evaluates models based on questions primarily in English. Yet, the top nine pre-trained base models are all Chinese-speaking models, including QWen, 01, InternLM, and DeepSeek. It’s hypothesized that models trained on different language families can perform better, akin to how learning a new language from a different family can broaden one’s understanding of the world.
Another interesting leaderboard, LMSYS Arena by Berkeley involves a blind test where evaluators choose the better response between two given to a prompt. Results are aggregated using the Elo algorithm. Alibaba’s QWen ranks first among all open-source models on this leaderboard. (Update: it has been overtaken by Cohere’s CommandR)
I created a table to capture the landscape of Chinese-speaking open-source models and their derivatives. While I might have missed some, the ecosystem is already broader than I initially thought.
Categories of Models:
- Models fine-tuned from LLAMA weights: LLAMA is powerful but lacks proficiency in Chinese and specific domain knowledge. By curating a massive dataset and using continuous pre-training or supervised fine-tuning, domain-specific Chinese-speaking models are created and released on Hugging Face, like Duxiaoman-DI’s Xuanyuan model, which excels in financial issues.
- Models pre-trained from scratch: These models take a step further. While using an architecture similar to LLAMA, they’re pre-trained from scratch without using LLAMA’s weights. This is way harder to do compared to the above and also avoids license restrictions. ChatGLM, for instance, has a huge ecosystem. (Note that GLM3 using LLAMA-ish structure not the early versions) Yi-Ko is Korean speaking model based on Yi/01 which might be interesting. Another interesting one is miniCPM is a 2B models that has the potential to be ran on edge devices like phones. TinyLLAMA also worth paying attention to. It aims to be pretrain a 1.1B LLAMA model on 3T tokens. The entire code base is open sourced and is super valuable if you want to learn how to pre-train a LLM.
- Other architectures: Models on the third category takes a different arch direction that is different from LLAMA. For example, QWen 1.5 and QWen 2 (based on the code) is exploring some new architectural directions. Ko-QWen is a Korean speaking model based on QWen base model if you’re interested. DeepSeek-MOE represents the first exploration of Mixture-of-Experts (MOE) in Chinese-speaking LLMs.
License and Community Contributions
Most Chinese-speaking models feature licenses that are friendly for commercial use.
Beyond LLMs, the Chinese researchers are also contributing great work to the entire open source community. For examples, in Jan. more than half of the top 10 trending Spaces are based on models trained by Chinese researchers. This includes Text-2-image models, synthetic voice generation and 3D Gaussian splatting models.
Looking Ahead to the Korean Ecosystem
The Korean ecosystem is also showing robust growth. The Upstage Korean LLM leaderboard has evaluated over 1,000 models. I am excited about the potential for a booming Korean-speaking LLM ecosystem.
Audience Questions
- Why do people open-source models?
The spirit of open source, which has been crucial for the development of AI from the early days, for example Google Open Sourced the industrial level deep learning framework TensorFlow in 2015. Researchers often need to publish their code and models to establish credibility. Startups use open sourcing as a strategy to attract attention and funding. Transparency in open sourcing also allows clients to interact with and refine technology, fostering community engagement and reducing support needs, which in turns greatly helps the B2B opportunity. - Key differences between Chinese and Western models?
There aren’t vast differences; both learn from each other. However, Chinese-speaking models tend to focus on low-resource languages, especially Asian languages, as well due to regional market dynamics.
Also Chinese speaking models seem to be legging behind in terms of total number of tokens being trained. For example, Gemma models are trained on 6T tokens, while QWen and DeepSeek are being trained on 2T-ish tokens. I think that this is related to the dataset being used. Chinese speaking dataset is way under-represented in the Open Source dataset world. If you’re thinking about creating datasets for low resource languages, we’re more than happy to be working with you. These type of work would be extremely valuable.
Government’s role
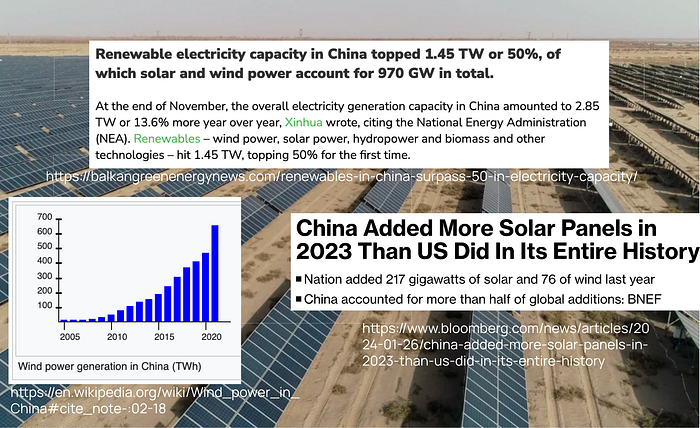
The Chinese government is encouraging building compute infrastructure on the west to get close access to renewable energy such as solar panels, hydropower and wind power. It also fits a bigger theme that government trying to get people out of poverty via big local infrastructure initiatives.
They’re also active in regulating potential misuse of technology. Two Gen-AI related laws are under discussion in China, emphasizing responsible use and transparency.